![image]()
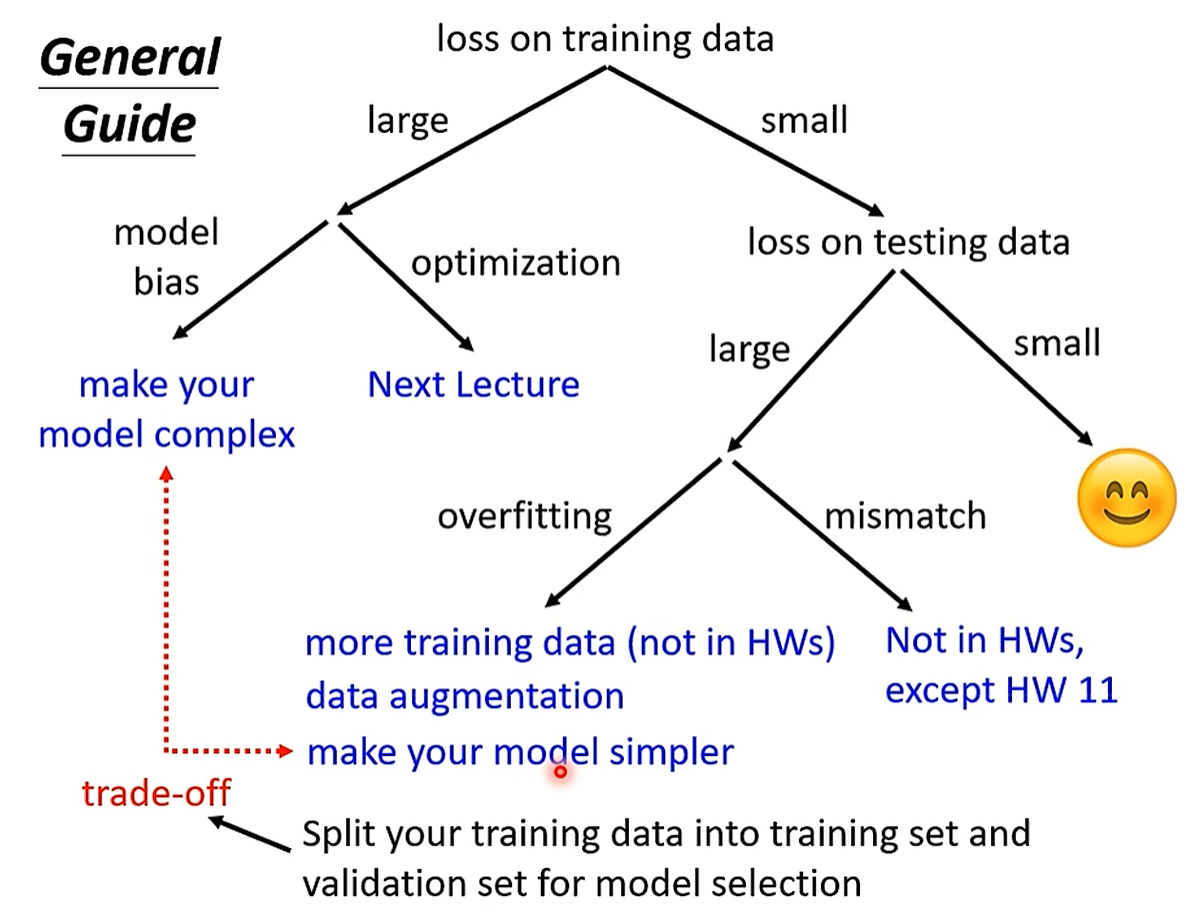
Model Bias
Problem: The model is too simple.
Solution: Redesign you model to make it more flexible.
More features or Deep Learning (more neurons, layers)
Optimization
Critical point (gradient is close to 0): Local minima / Saddle point
H: Hessian Matrix
L(θ)≈L(θ′)+21(θ−θ′)TH(θ−θ′)
记 vTHv=21(θ−θ′)TH(θ−θ′)
-
Local minima:
For all v, vTHv>0→Around θ′:L(θ)>L(θ′)
H is positive definite = All eigen values are positive.
-
Local maxima:
For all v, vTHv<0→Around θ′:L(θ)<L(θ′)
H is negative definite = All eigen values are negative.
-
Saddle point:
Sometimes vTHv>0, Sometimes vTHv<0
Some eigen values are positive, and some are negative.
error surface 维度很高,因此 local minima 很少。
Model Bias v.s. Optimization Issue
e.g. 56-layer 比 20-layer 更差,不是 overfitting,而是 optimization issue。
建议:先使用简单的 model,不容易出现 optimization issue,
Overfitting
An extreme example:
f(x)={y^irandom∃xi=xotherwise
Solution:
Batch
-
Large batch: long time for cooldown, but powerful
-
Samll batch: short time for cooldown, but noisy
因为有 GPU 平行运算(显存换时间),所以跑一个 epoch,large batch update 的次数更少,更有效率
Warning: Large batch size 容易出现 optimization fails
|
Samll |
Large |
| Speed for one update (no parallel) |
Faster |
Slower |
| Speed for one update (with parallel) |
Same |
Same(not too large) |
| Time for one epoch |
Slower |
Faster |
| Gradient |
Nosiy |
Stable |
| Optimization |
Better |
Worse |
| Generalization |
Better |
Worse |
Momentum
Learning Rate
震荡,Loss 不再减少,但是 Gradient 不为 0
Learning rate 要为每一个参数客制化
θit+1←θit−ηgit,git=∂θi∂L∣θ=θt
θit+1←θit−σitηgit
Adagrad
Root Mean Square 均方根
θi1←θi0−σi0ηgi0, σi0=(gi0)2=∣gi0∣θi2←θi1−σi1ηgi1, σi1=21[(gi0)2+(gi1)2]…θit+1←θit−σitηgit, σit=t+11j=0∑t(gij)2
RMSProp
0<α<1
θi1←θi0−σi0ηgi0, σi0=(gi0)2θi2←θi1−σi1ηgi1, σi1=α(σi0)2+(1−α)(gi1)2…θit+1←θit−σitηgit, σit=α(σit−1)2+(1−α)(git)2
Adam: RMSProp + Momentum
Learning Rate Scheduling
θit+1←θit−σitηtgit
Learning Rate Dacay
递减
Warm Up
先增大再减小